I’m not an epidemiologist, but in a past life I was a mathematical modeler of human memory systems, and later did modeling to test theories about businesses. Modeling is an essential tool in science. But they are almost always wrong.
Last week we were treated to Trump and a group of scientists discussing epidemiological models. I thought they did a pretty good job, but I also see a lot of misunderstandings about what models can and cannot be. So let’s pause and talk about modeling.
Models are generally used in two ways:
- To test theories. Got an idea how the weather system works? How humans retrieve memories? How epidemiology works? I don’t care about your intuitions – go build a formal mathematical model and test it against real phenomena. Newton’s equations for gravity are a great example – by formalizing his ideas and building a model that makes predictions, he proved that his ideas predicted nature.
- To make predictions. Just because you’ve predicted the phenomena you’ve tested doesn’t mean you can predict future phenomena. Models are built upon and tuned by past observations. Also, as we’ll see, a model’s predictions are reliant on the free parameters of the model; if you don’t know those, you can’t really predict. More on this later.
Note that neither of these means your model is “correct” or explains the nature of reality. One of the most influential people in my life on this topic was my Ph.D. advisor, Doug Hintzman. You can read his thoughts here
All this said, models can be powerful tools and in the best cases predict reality far beyond their initial intent. At the very least, they force a theorist to rigorously test their ideas.
So on to epidemiology. One criticism I’m seeing is that different models differ in their predictions. I have been astonished they’re as similar as they are! In fact, I think most of the models themselves are very similar in design, but different teams are starting with different parameters, resulting in very different predictions. Let’s explain parameters…
Modeling and free parameters.
Models are just complex algorithms. You pick a set of inputs (aka parameters), run the model, and get a prediction. For gravity, the inputs/parameters are the two masses and the distance between them. The output is the force between the masses. This is an excellent model in that it has very few easily measured parameters and can be applied with high accuracy across (almost) all of the universe. A good model thus has a few fixed or measured parameters and predicts a lot.
Things get tricky when you either have many parameters or the parameters are uncertain or poorly measurable. Epidemiological models are like this. Take the University of Washington’s model, below:
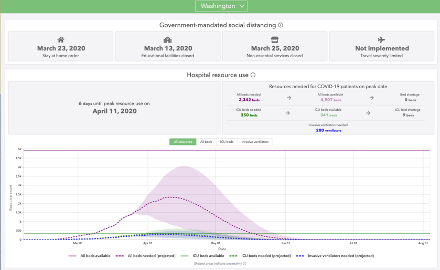
This model is trying to take some parameters and predict if our peak needs will exceed our capacity. To be exact:
Explicitly stated parameters:
- Amount and timing of social distancing measures (easily measured)
- Number of hospital beds (easily measured)
- Number of ICU beds (easily measured)
- Date of first infection (and as time goes by, course of the pandemic and current number of infections). (easily measured)
- Time from infection to symptoms/testing (uncertain)
- Time from symptoms to hospitalization (uncertain)
- Time from hospitalization to ICU (uncertain)
- Time in ICU (uncertain)
- Time to Death (easily measured)
That’s several parameters, but I think there are also a number of Implicitly stated parameters:
- Effectiveness of various social distancing measures (uncertain)
- Extent of compliance with social distancing measures (uncertain)
- Transmissiveness of the virus (uncertain)
- Likelihood an infection results in hospitalization (uncertain)
- Likelihood a hospitalization proceeds to ICU/ventilator (uncertain)
- Likelihood COVID is fatal (uncertain)
Now, in many of these cases you might hope to FIX these parameters instead of having them vary (FREE parameters) based on past history. But that’s hard. For example, many of these will be different in different communities. Italy had an older population of smokers and so might have much higher 4, 5, and 6. They like to hug and kiss so 2 might be low and 3 might be high. China’s authoritarian system might mean 2 is very high.
I could go deeper – for example the WA model is more upbeat than the OH model because Ohio assumes the average ventilator patient spends more time on the ventilator, (introducing yet another parameter!) meaning a ventilator can serve more patients per month in the WA model than the OH one.
And the parameters are hard to measure! We simply don’t have the data to really nail down the parameters exactly. So there are error bars around the parameters, and then the model goes and multiplies all that uncertainty together! The WA team’s model above does indicate all of this with the HUGE error region around its predictions.
So far, it’s done pretty well at predicting the rise of the curve, but what’s coming is harder. Now we’ll see if their parameter set around the impact of social distancing will predict when we bend the curve into the negative range – with cases finally decreasing instead of increasing. I think there’s a huge amount of uncertainty there and that makes me very nervous.
To close on an upbeat note, have the models been useful? Certainly! They’ve accomplished several essential things:
- They demonstrated the counterintuitive notion that a small number of infections can quickly grow catastrophically, spurring a lot of Governors into and populations into action.
- They’ve driven a mad scramble for capacity planning and execution – beds, ICUs, ventilators.
- Fauci was able to eventually use the models to get the Trump administration to finally shift their messaging.
- They were also apparently essential to convincing Trump not to open for Easter – something he dearly wanted to do.
It’s also worth noting that the models are getting better every single day. We get data on the parameters, data on the actual result day by day, and as we do the models are converging, just as they should.
